
UFT One password encoding
A look into insecure 'encryption' used in enterprise QA tooling
Introduction
UFT One (Unified Functional Testing) is a popular tool used by QA teams to automate functional and regression testing across desktop, web, and mobile applications. It allows users to build complex test cases which often involve sensitive configuration parameters, including database and application credentials.
To hide these sensitive strings, users are provided with an encoder that transforms passwords into a series of hexadecimal characters. Looking at the documentation on the official website, I was surprised to see the following warning:
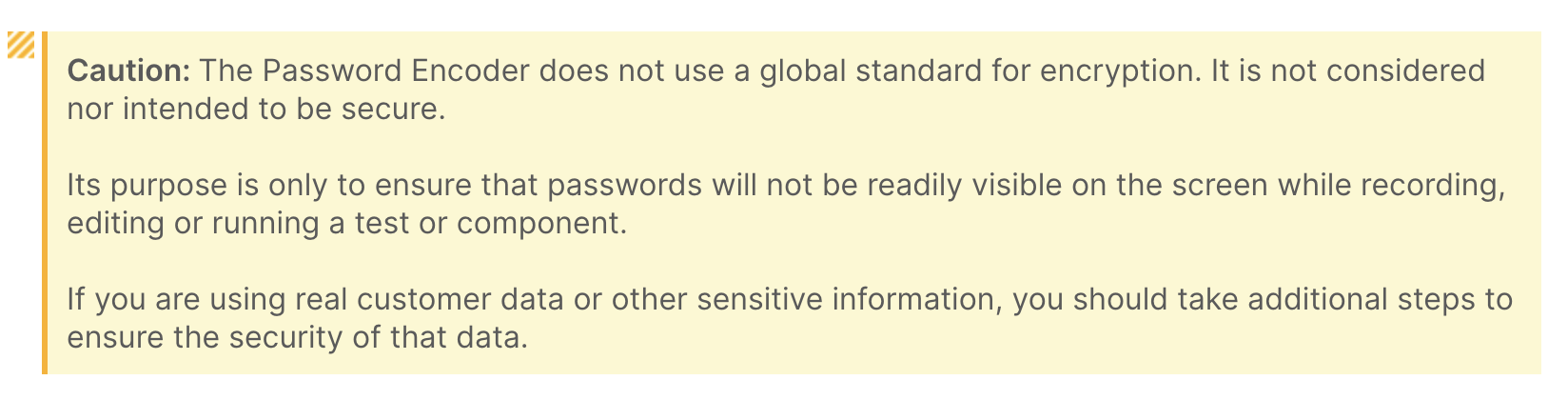
Even with a clear warning that the tool is not meant to be secure, some users are doomed to treat encoding as encryption. After receiving a tipoff that these sensitive strings often show up in public GitHub repositories, I decided to take a closer look.
Entry Point for Reversing
Multiple tools, GUI and CLI, are available to create "secure strings", but as far as I know, they all use the same DLL under the hood.
Once I isolated the relevant DLL, I built a C wrapper to confirm that the encoded values can be decoded without the need for a key. It also gave me a reliable way to validate the results I would obtain once I reimplement my own solution.
From an automated functional test case:
Dialog("DialogLogin").WinEdit("Password").SetSecure "64fa9bce7a0b0f7c6e07f2708e0e"
The value can be decrypted by passing it to the wrapper:
> .\decrypt-wrap.exe 64fa9bce7a0b0f7c6e07f2708e0e
hunter2
If our goal was to decode a single string, this could be the end of the project. But I'd like to understand the algorithm enough to make my own cross-platform implementation that doesn't rely on the original DLL.
I loaded the DLL into IDA and looked at the exports:
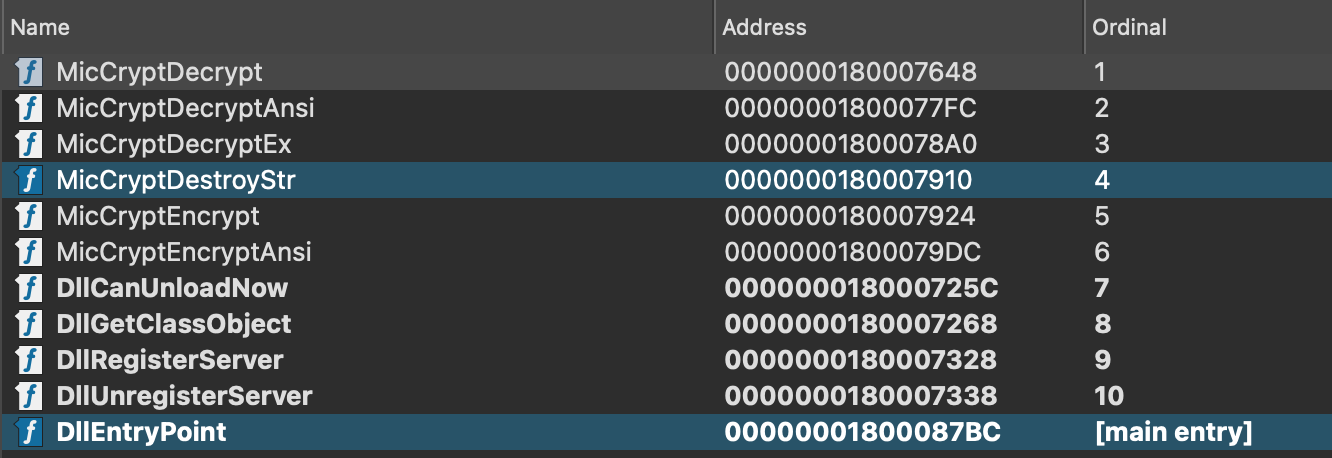
Having the procedure referenced as encoding in some places and encryption in others usually means we're dealing with flawed encryption.
Static Analysis: Decryption Algorithm
Both MicCryptDecrypt() and MicCryptDecryptAnsi() are wrappers for the same decryption routine, with the difference that MicCryptDecrypt() first makes a call to WideCharToMultiByte().
Digging into the central decryption function, we can see that the first 4 bytes of the secure string are parsed to create a key and that the rest of the string is decoded character-by-character:
else
{
key = p_key[3] | ((p_key[2] | ((p_key[1] | (*p_key << 8)) << 8)) << 8);// key in 4 first bytes
if ( length > 4LL )
{
char_to_decrypt_ptr = (char *)(p_key + 4);// 4 first bytes (key) removed from string
do
{
decrypted_byte = xor_cipher(*char_to_decrypt_ptr, &key);
*decrypted_str = decrypted_byte;
char_to_decrypt_ptr = decrypted_str + 1;
}
while ( v28 != 1 );
p_key = (unsigned __int8 *)v30;
}
p_key[length] = 0;
v22 = (_BYTE *)maw_malloc(length - 3);
memcpy(v22, v30 + 1, length - 3);
if ( a2 )
*a2 = length - 4;
}
This proves that the key is always included with the ciphertext and doesn't require any other secret data.
The actual cipher is an xor-based encryption in multiple stages using the hardcoded constant 0x87654255:
int __fastcall xor_cipher(char char_to_encrypt, unsigned int *key)
{
unsigned int v3; // r8d
unsigned int v4; // edx
unsigned int v5; // r8d
unsigned int v6; // edx
unsigned int v7; // r8d
unsigned int v8; // edx
unsigned int v9; // r8d
unsigned int v10; // edx
int result; // eax
v3 = *key >> 1;
if ( (*key & 1) != 0 )
{
char_to_encrypt ^= 0x80u;
v3 ^= 0x87654255;
}
v4 = v3 >> 1;
if ( (v3 & 1) != 0 )
{
char_to_encrypt ^= 0x40u;
v4 ^= 0x87654255;
}
v5 = v4 >> 1;
if ( (v4 & 1) != 0 )
{
char_to_encrypt ^= 0x20u;
v5 ^= 0x87654255;
}
v6 = v5 >> 1;
if ( (v5 & 1) != 0 )
{
char_to_encrypt ^= 0x10u;
v6 ^= 0x87654255;
}
v7 = v6 >> 1;
if ( (v6 & 1) != 0 )
{
char_to_encrypt ^= 8u;
v7 ^= 0x87654255;
}
v8 = v7 >> 1;
if ( (v7 & 1) != 0 )
{
char_to_encrypt ^= 4u;
v8 ^= 0x87654255;
}
v9 = v8 >> 1;
if ( (v8 & 1) != 0 )
{
char_to_encrypt ^= 2u;
v9 ^= 0x87654255;
}
v10 = v9 >> 1;
if ( (v9 & 1) != 0 )
{
result = char_to_encrypt ^ 1;
v10 ^= 0x87654255;
}
else
{
result = (unsigned __int8)char_to_encrypt;
}
*key = v10;
return result;
}
The function's xrefs show that the cipher is called by both the encryption and decryption routine, hinting that the process is fully reversible and using exactly the same transformation:
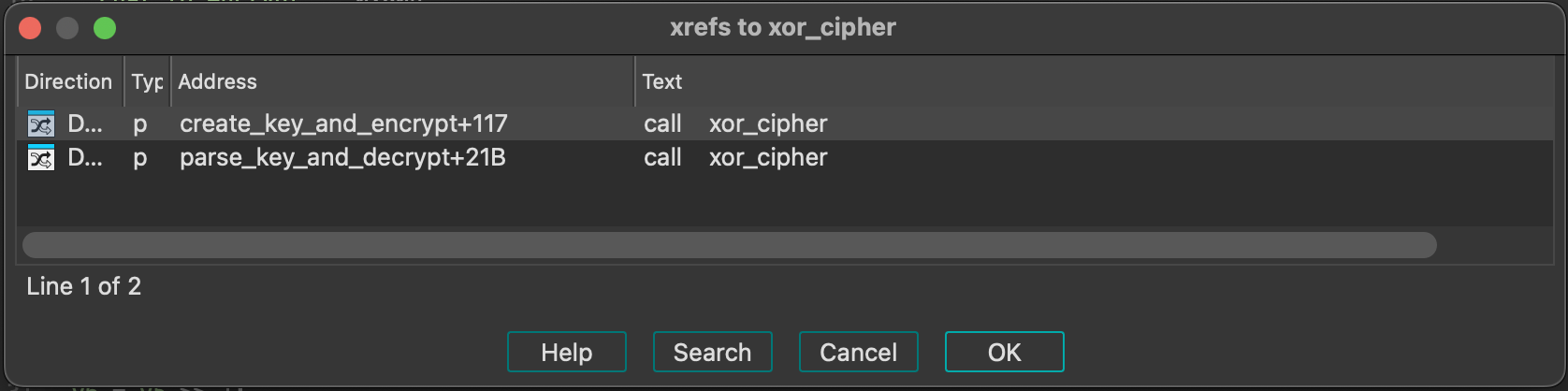
We now have enough information to reimplement the cryptographic model, but I'm still curious about one detail: every time we encrypt a string, the result is different. That would be an expected behaviour if the key was randomly generated every time, but the first bytes of the keys I generate are always really similar. Before ending the research phase, I'd like to analyze the predictability of the key.
Key generation
Looking at the decompilation output for the encryption algorithm, we can see that the key generation is not random at all:
current_time = time64(0LL);
...
if ( !current_time )
current_time = 1;
encryption_key = current_time;
v8 = (int)end_string_ptr + 20LL;
if ( v8 <= (int)end_string_ptr + 5LL )
v8 = 0xFFFFFFFFFFFFFF0LL;
v9 = alloca(v8 & 0xFFFFFFFFFFFFFFF0uLL);
p_maybe_key_enc = &encryption_key;
LOBYTE(encryption_key) = HIBYTE(current_time);
BYTE1(encryption_key) = BYTE2(current_time);
BYTE2(encryption_key) = BYTE1(current_time);
HIBYTE(encryption_key) = current_time;
if ( (int)end_string_ptr > 0 )
{
str_size = (unsigned int)end_string_ptr;
key_size = end_string_ptr + 4;
do
{
cipher_result = xor_cipher(*char_to_encrypt_ptr, &encryption_key);
It is simply the 32-bit output of time64(), which makes it predictable. Of course, the keys is always included with the ciphertext which makes this observation almost useless, but it's nice to know that even if it wasn't, we would still have a reliable way to immensely reduce the keyspace to a bruteforceable size.
Python implementation
I wrote a Python version of the algorithm that matched the observed process. I tried to stick to the analyzed implementation as much as possible, keeping the time-based key and the weak cipher.
#!/usr/bin/env python
import sys
import time
class UFTOneCrypt:
"""
UFTOneCrypt()
Class can be initialized with an encrypted string
If none is provided, parse_string() must be called manually to set key and payload
"""
def __init__(self, encrypted_string=None):
self.key = 0
self.tmp_key = 0
self.payload = ""
self.UNK_CONST = 0x87654255
if encrypted_string:
self.parse_string(encrypted_string)
"""
UFTOneCrypt.parse_string()
Extracts the key and encrypted payload from the hex string
"""
def parse_string(self, encrypted_string):
if len(encrypted_string) <= 8:
raise Exception("UFT Encrypted hex string must be longer than 4 bytes")
key_str = encrypted_string[0:8]
enc_str = encrypted_string[8:]
try:
key_test = int(key_str, 16)
payload_test = int(enc_str, 16)
except:
raise Exception("UFT Encrypted string must be hexadecimal")
self.key = int(key_str, 16)
self.payload = enc_str
"""
UFTOneCrypt.decrypt()
Decryption routine
Sends bytes to UFTOneCrypt.xor_cipher() and decodes the output as UTF-16
Returns the decrypted payload
"""
def decrypt(self):
if self.key == 0:
raise Exception("UFT Key is not set. Use parse_string(encrypted_string) to parse an encrypted string")
if self.payload == "":
raise Exception("UFT Payload is not set. Use parse_string(encrypted_string) to parse an encrypted string")
self.tmp_key = self.key
l = int(len(self.payload)/2)
result = bytearray()
for x in range(0, l):
index = x*2
current_byte_str = self.payload[index:index+2]
current_byte = int(current_byte_str, 16)
decrypted_byte = self.xor_cipher(current_byte, self.tmp_key)
result.append(decrypted_byte)
return result.decode('utf-16')
"""
UFTOneCrypt.encrypt()
Encryption routine
Calls for a new key generation and sends bytes to UFTOneCrypt.xor_cipher()
Returns the encrypted payload
"""
def encrypt(self, plaintext):
# utf-16 encoding
wide_plaintext = plaintext.encode('utf-16')[2:]
wide_plaintext_hex = wide_plaintext.hex()
l = int(len(plaintext)*2)
# key generation
self.generate_key()
self.tmp_key = self.key
# key as the beginning
result = hex(self.key)[2:]
for x in range(0, l):
index = x*2
current_byte_str = wide_plaintext_hex[index:index+2]
current_byte = int(current_byte_str, 16)
encrypted_byte = self.xor_cipher(current_byte, self.tmp_key)
hex_char = hex(encrypted_byte)[2:]
# Left Padding
if len(hex_char) == 1:
hex_char = "0" + hex_char
result += hex_char
return result
"""
UFTOneCrypt.xor_cipher()
Used for encryption and decryption
Should not be called manually
Returns a single decrypted byte
"""
def xor_cipher(self, current_char, key):
x = key
v = 0
for i in range(0,8):
v = x >> 1
if ( (x & 1) != 0):
current_char ^= int( (0x80 /(2 ** i) ))
x = v ^ self.UNK_CONST
v = x
else:
x = v
self.tmp_key = v
return current_char
"""
UFTOneCrypt.generate_key()
Creates a new encryption key based on the current time
It stays true to the original implementation even though time is not a secure random generator
"""
def generate_key(self):
time_string = hex(int(time.time()))[-8:]
self.key = int(time_string, 16)
def __str__(self):
return self.decrypt()
def main():
if len(sys.argv) > 1:
encrypted_string = sys.argv[1]
else:
encrypted_string = input("Enter the encrypted hex string: ")
# Encrypt
"""
uft = UFTOneCrypt()
encrypted_string = uft.encrypt("This is the string to encrypt")
"""
# Decrypt
uft = UFTOneCrypt(encrypted_string)
print("Key: %s" % hex(uft.key))
print("Encrypted payload: %s" % uft.payload)
print("Decrypted string: %s" % uft.decrypt())
return 0
if __name__ == "__main__":
main()
Here's the decoder in action:
$ python uftonecrypt.py 64fa9bce7a0b0f7c6e07f2708e0e
Key: 0x64fa9bce
Encrypted Payload: 7a0b0f7c6e07f2708e0e
Decrypted string: hunter2
I also published it on GitHub.
Semgrep Rule
I created a Semgrep rule to detect the use of UFT One secure strings in source code because these encoded credentials are often committed to version control and public repositories under the mistaken belief that they're safely encrypted.
rules:
- id: uftone-setsecure-hex
message: "Potential UFT One secure string passed to SetSecure. See https://pebwalker.com/uftone-decryption/"
severity: "WARNING"
languages: ["generic"]
metadata:
category: "security"
technology: "UFT One"
references:
- "https://pebwalker.com/uftone-decryption/"
notes: "Matches SetSecure(\"HEX...\") or SetSecure \"HEX...\". Requires even-length hex, ≥10 hex chars (5 bytes): 4-byte key + payload."
pattern-regex: "(?i)\\bSetSecure\\s*(?:\\(\\s*)?[\"']((?:[0-9a-f]{2}){5,})[\"']\\s*\\)?"
By scanning for the SetSecure usage patterns, teams can catch and remediate leaking credentials before they propagate, improving security hygiene and raising awareness that this encoding is not actual protection.
Conclusion
This encryption was never meant to be "unbreakable", as shown in the documentation. It was designed as a form of obfuscation. And that's fine if it's treated that way: people misusing it and treating it like secure encryption is the real problem.
But maybe naming the method SetSecure sets the wrong expectation? In practice, data that only looks encrypted can be worse than cleartext because its illusion of security encourages risky overexposure and lax handling.